raft实现
Lab3 Raft实现
Raft的原理是通过一个日期机制和日志复制以及持久化保证一致性,每台服务器都有一个 Term,每个 Term 只会有一个 Leader,每次操作由 Leader 先追加日志再将日志同步给其他 follower,只要有多数确认了日志,则可以提交日志,即操作成功。我们通过在选举 leader 时增加对日志的限制即可保证被提交的日志一定不会被覆盖。
3A
3A 主要是不考虑状态机的情况下,实现 Raft Leader选举和心跳机制,确保选举出单一 Leader,如果没有故障就保持 Leader,如果 Leader 故障或者包丢失,则选举新的 Leader
ticker实现
我们需要实现超时机制,在一定时间后没有心跳,则我们需要进行选举
选举实现
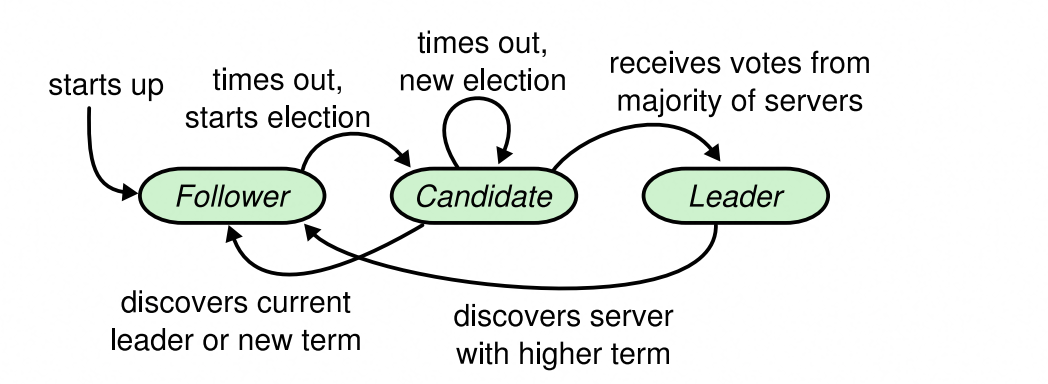
状态转移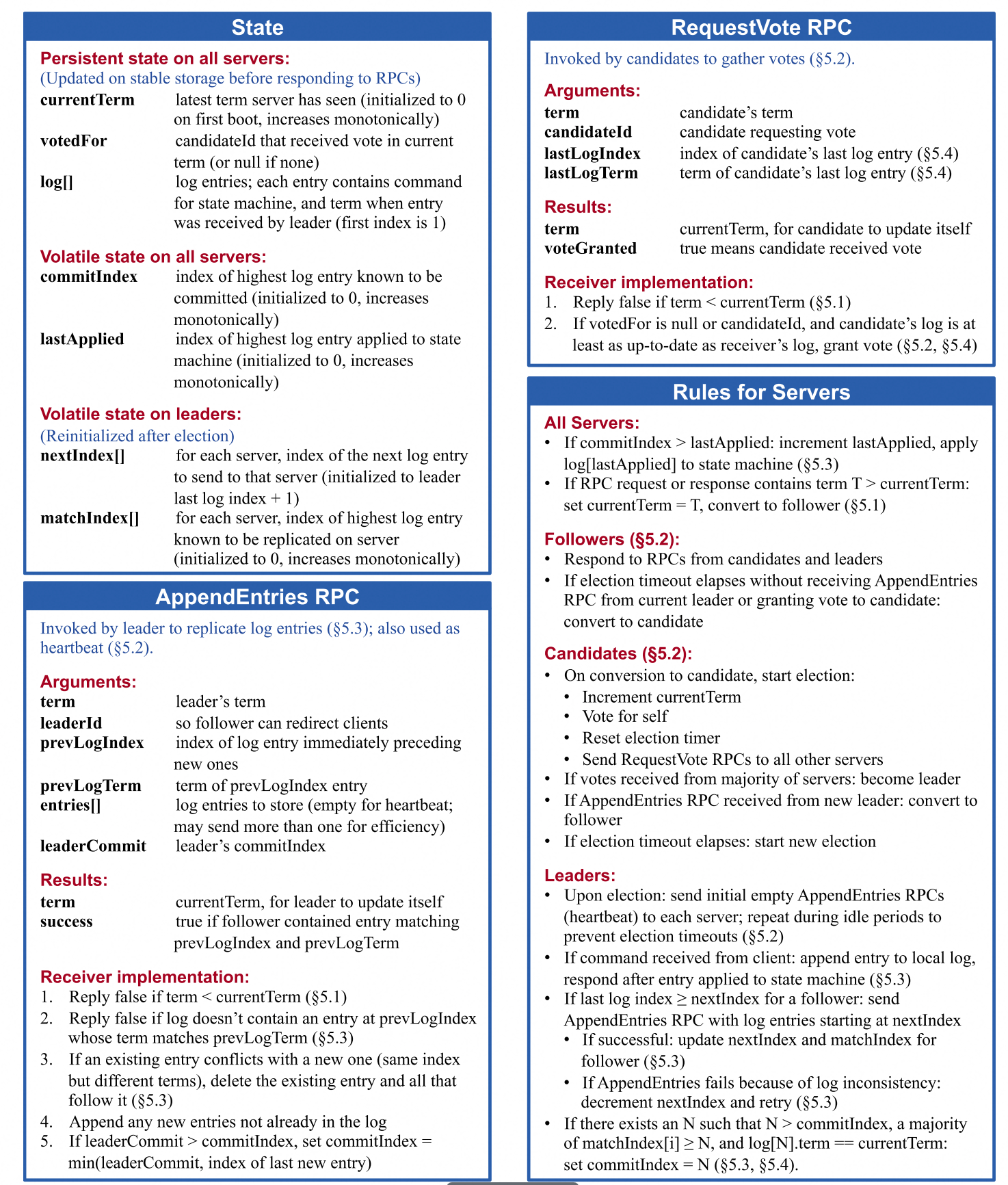
API 参考
具体实现参照原论文中状态转移和 API 定义即可,需要注意的点如下
- 在向其他服务器发送 RequestVote 时,需要将锁释放,不然有可能出现多个 Candidater相互要票却无法投票的情况,因为投票也需要加锁,所以会产生死锁
- 在一台服务器决定是否投票时,如果收到的 Term 大于自身 CurrentTerm,需要更新自身 Term 并更新 VoteFor(我没更新 VoteFor 卡了好久),因为没更新 VoteFor 会导致它进入下一个 Term 但是不能投票的情况出现,进而导致选举不出 Leader
- 发送心跳时也尽量不要锁整个函数,如果出现特殊情况也可能导致死锁,出现两个 Leader 虽然不是同一 Term 但有可能相互要锁导致死锁。
3B
Log Replication(日志复制)
一次操作的控制流如下
- 客户端调用我们提供的 Start(command)
- Leader 将 command 追加到 log
- 后台向其他 server 发送 AppendEntries,超过 n/2 个 server 后更新 commitIndex,后台异步进行 apply
- commitIndex 是根据每次 AppendEntries 进行更新的,事实上 commit 这个操作并没有实质性对 log 的操作,只是修改了 commitIndex 用于提交
- 后台异步进行 apply(使用定时任务或条件变量(即只在 commitIndex 更新时通知 apply))
我们需要做的就是在之前选举的基础上增加对日志的限制,即在选举时保证一个 server 只会对日志比它新的 candidater 投票,具体逻辑是如果 candidater 的 lastLogTerm 比当前 server 的大,或者如果 Term 一样,则比较 Index,如果 args 的下标大于等于当前 server,说明它的更新,且他们俩曾经在同一个 leader 领导下,我们这样可以证明一个被提交的 log 一定不会被覆盖,原因如下,在 n 个 server 中,有超过 n/2 的 server 包含这条日志,则选举时,至少 n/2 + 1 个 server 不会给一个不包含此日志的candidater 投票,因此一定不会出现一个 leader 不包含此日志,出现的 leader 一定包含所有被提交的日志。一条没被提交的日志有可能出现被覆盖或者不被覆盖,对此 raft 不做保证。
一些bug
进行 AppendEntries 时写出了这样的代码
1 | args[i] = AppendEntriesArgs{ |
这里因为在args[i]初始化之前只是分配了内存,所以args[i].PrevLogIndex在赋值是恒为 0,就会导致Follower 虽然 log 和 Leader 相同,但是收到的logTerm 是 0,因此不能进行 appendEntries
在log的 struct 中将 LastTerm 写成了 lastTerm,进行 rpc 是传递的为 0,导致虽然日志一样,但无法给 leader 投票
3C
persistence(持久化)
我们需要保证每次服务器重启时已经做过的操作不会丢失,因此需要将log 保存下来,但是为了保证一致性,即选举的一致性和日志的一致性,我们需要将当前的 Term 以及 voteFor 持久化,避免出现重启后 Term 倒退或者同一个 Term 多次投票的情况,具体实现逻辑只需要在每次修改日志、Term 或者 VoteFor 时调用 Persist()方法,将这些状态序列化之后保存,然后每次启动调用 Make()函数时调用 readPersist()即可
一些bug修复
由于3A 和 3B 的测试较为松弛,因此很多在选举和日志复制中遗漏的问题会在这里 3C 中显现。
- 在收到 AppendEntries 的 Reply 时,我们需要检验当前 Term 是否与args 的 Term 一致,防止过期请求
- 在Follower 收到 AppendEntries 时需要保证 AppendEntries 处理的幂等性,比如说因为网络问题出现了两条 AppendEntries 乱序,即log 比较长的 rpc 先到,之前的代码会导致在比较短的 AppendEntries 到达的时候已经把log 接过了,我们直接采取把超过 nextIndex的 log 截断并接上新的,这样会出现一种情况是我们正在 apply 某一段 log,然后在这个过程中这一段log 被删除了,就会出现 apply 错的问题,这里我们的思路是只有在发来的 log 和原本 log 出现矛盾时才进行覆盖,不然就遍历完之后进行拼接,保证了被覆盖掉的一定是旧的日志,已经被追加过的可能被 commit 的日志不会被覆盖。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26// 4. 处理日志条目
if len(args.Entries) > 0 {
// 检查是否有冲突的日志条目
conflictIndex := -1
for i, entry := range args.Entries {
logIndex := args.PrevLogIndex + 1 + i
if logIndex < len(rf.log.entries) {
if rf.log.entries[logIndex].Term != entry.Term {
conflictIndex = logIndex
break
}
} else {
// 超出现有日志长度,直接追加
conflictIndex = logIndex
break
}
}
if conflictIndex != -1 {
// 删除冲突的条目
rf.log.entries = rf.log.entries[:conflictIndex]
// 追加新条目
rf.log.entries = append(rf.log.entries, args.Entries[conflictIndex-args.PrevLogIndex-1:]...)
updateState = true
}
} - 如果我们要关闭服务器,即 kill,需要唤醒 apply 进程,把 apply 进程退出,不然可能会出现 apply 进程在睡眠,然后重启之后,出现一个新的 apply 进程,但是它们绑定的是同一个通道,会出现 apply out of order的问题
1
2
3
4
5
6func (rf *Raft) Kill() {
atomic.StoreInt32(&rf.dead, 1)
// Your code here, if desired.
rf.applyCond.Broadcast() // 通知所有等待的 applier goroutine 停止
DPrintf("[S%v][%v][T%v] killed", rf.me, rf.roleString(), rf.currentTerm)
}
nextIndex 逻辑优化
原论文中 RPC 实现是如果 PrevLog 和当前的 log 出现冲突,则返回 false,并将 nextIndex - 1,如果在 Leader 和 follower 的冲突比较大时,可能会造成很多冗余的 RPC,我们对此进行优化,思路是如果 AppendEntries RPC 失败,follower 返回一个 XIndex,用于 leader 更新 nextIndex,具体实现如下
- 如果 prevLogIndex > lastIndex,则将 nextIndex 更新为 lastIndex + 1 即可
- 如果 prevLogIndex <= lastIndex 且 这两条日志的 log 不同,我们希望找到一个相同的点,我们可以一次跳一个 Term,就是把和 lastIndex 相同的 Term 的 log 都跳过去,返回这个 Index
1 | if rf.log.entries[args.PrevLogIndex].Term != args.PrevLogTerm { |
后续加上快照这里应该需要修改一下
3D
snapshot
一个系统运行长时间后会导致 log 变得很长,因此我们考虑使用快照来压缩日志,将 index 前的日志全部删除,并保存当前状态机的 snapshot,维护一个 baseIndex,代表当前日志从 baseIndex 开始,每次快照后使 baseIndex = lastIncludedIndex + 1,参照论文实现 InstallSnapshotRpc 即可
引入快照后需要考虑的一些地方
- Leader 发送 AppendEntries 时,如果 nextIndex 已经被压缩,向 Follower 发送 InstallSnapshotRPC
- Follower接收到 AppendEntries 时,如果 PrevLogIndex + len(entries) < baseIndex,直接返回成功保证幂等,如果 PrevLogIndex < baseIndex 但 PrevlogIndex + len(entries) >= baseIndex,我们将发送过来的 entries 的被压缩的一部分进行截断后再处理
- 修改 readPersist,将 rf.snapshot置为读取到的 snapshot
- 修改 AppendEntries 的 Xindex 逻辑
1
2
3
4
5
6
7
8
9
10
11
12if args.PrevLogIndex >= rf.log.baseIndex && preEntry.Term != args.PrevLogTerm {
// 找到冲突term的第一个索引
for i := args.PrevLogIndex; i >= rf.log.baseIndex; i-- {
entry, _ := rf.log.Get(i)
if entry.Term != preEntry.Term {
reply.XIndex = i + 1
break
}
}
return
} - 修改 applier 逻辑,先加锁获取到要发送的消息,如果存在 rf.snapshot,则发送 snapshot 消息,不然发送正常消息,保证每轮只发送一类消息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15func (rf *Raft) applier() {
for !rf.killed() {
rf.mu.Lock()
if rf.killed() {
rf.mu.Unlock()
break
}
for rf.applyIndex == rf.commitIndex {
rf.applyCond.Wait()
}
msgs := rf.getMsgs()
rf.mu.Unlock()
rf.sendMsgs(msgs)
}
}
